Maximum Likelihood Estimation
Basic Idea
As a first try at classifying images, we constructed a simple statistical model. Since each image consists of a small number of points that make up a path, we could think about those points as being iid draws from a two-dimensional density determined by the food class.
Then, we could compare sample points from each drawing to our smooth empirical density estimate for each food class. We can calculate a log-likelihood that the drawing came from each of the thirty food classes. Finally, we predict that the image came from the class with the largest log-likelihood.
We give an example of this procedure below.
Figure 1: Apple Drawing Overlayed on the Apple and Broccoli Density Estimates
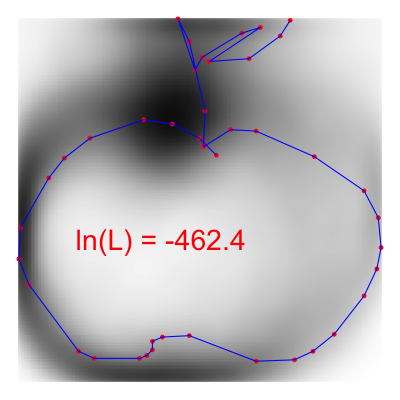
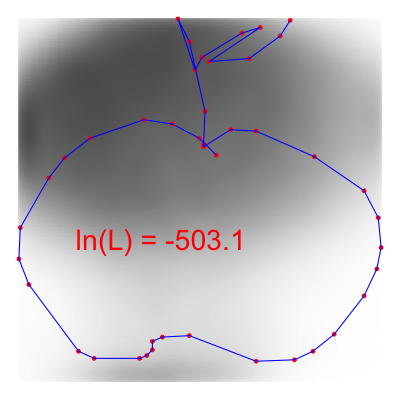
Above we plot a single apple drawing on top of our smoothed density estimate for the apple and broccoli drawings. The red points represent the sampled points along the image path from the original data. We see that where the red points intersect the Apple kernel in higher-density regions than where the red points intersect the broccoli kernel. Hence, if we sum up the log likelihoods at each of the red points for each class, we see that the likelihood that this image is from the apple class (-462) is higher than the likelihood it is from the broccoli class (-503).
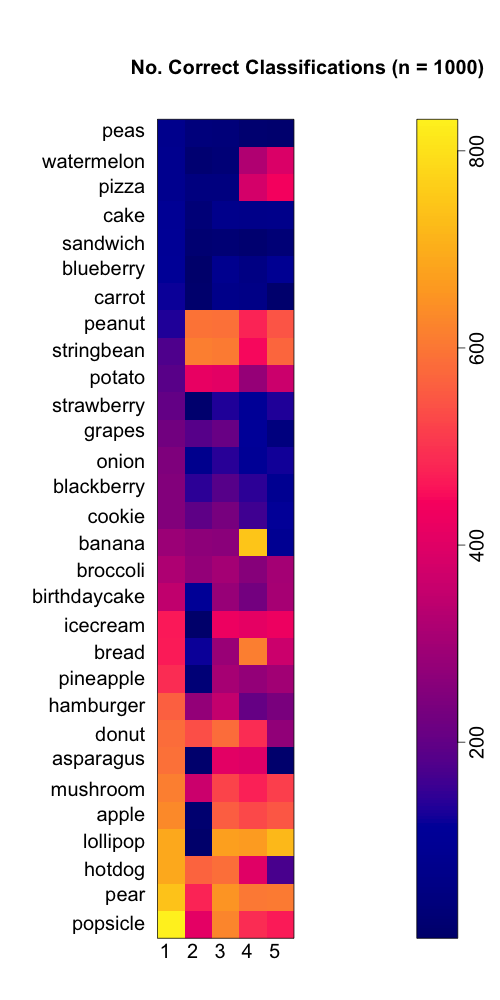
Model Results
Using this approach, we labeled 1,000 imgaes from each food class. Of the 30,000 images classified, 35.5% were classified correctly. With complete random guessing, we would expect to classify correctly only 1 in 30 images (3.3%)
Figure 2: Classification Matrix
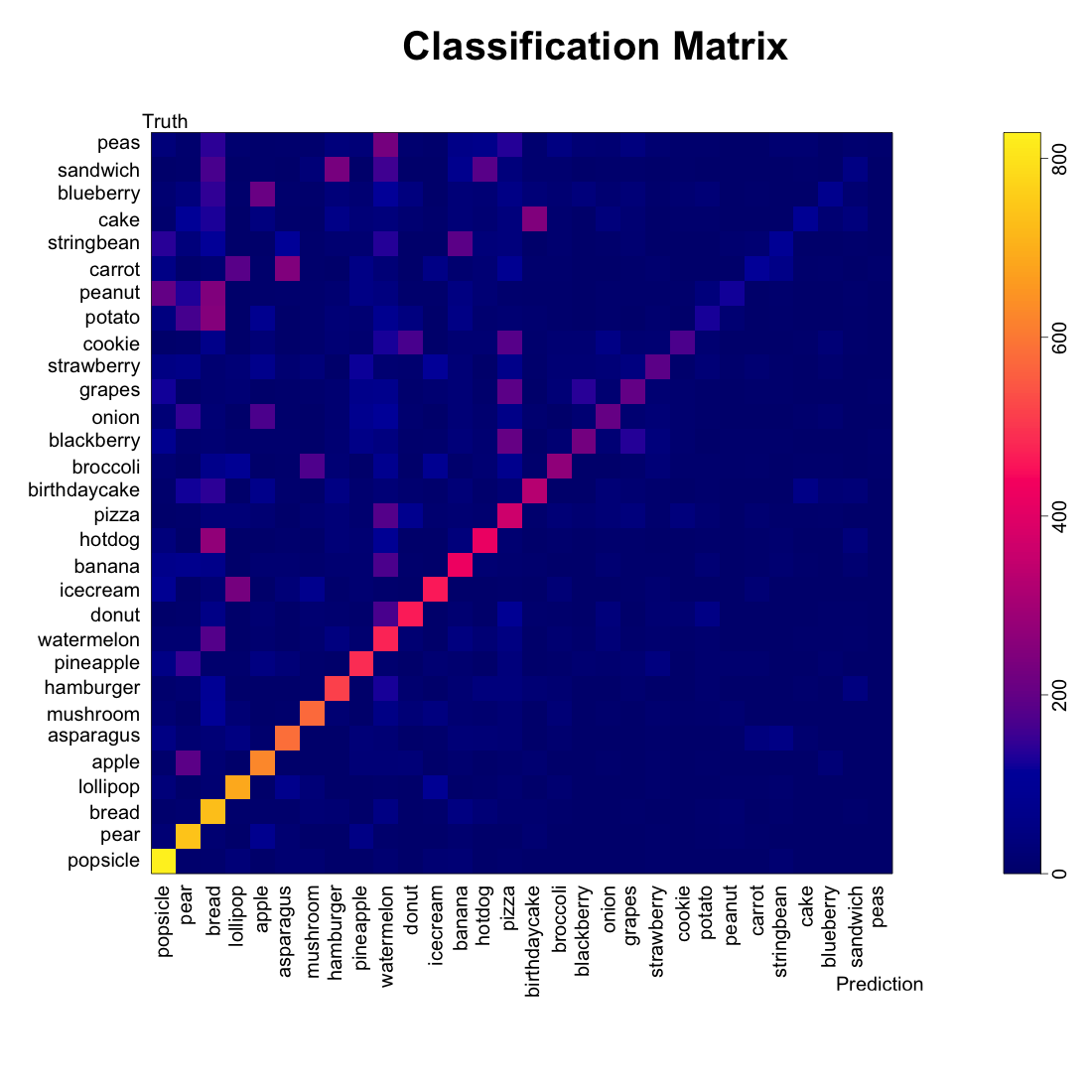
The classification matrix above was sorted by the class-specific accuracy, and we can see that the accuracy depended highly on the food class: we can classify popsicles, pears, and bread very well (> 700 images each) while we classify cake, sandwiches, and blueberries poorly (< 100 images each).
We also see patterns in the mis-classification–cakes and birthday cakes were often cross-classified. String beans were often labeled as bananas. Broccoli and mushrooms were confused.
We see that certain labels (bread, watermelon, pizzas) seemed to be catch-alls for other foods. We asked whether our algorithm was just labeling MORE things as popsicles, pears, and bread.
Figure 3: Class Positive Predictions and Sensitivity
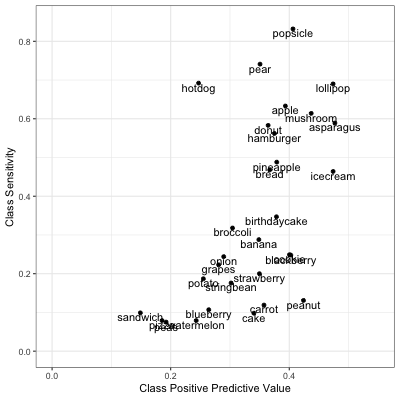
While we were able to label ~80% of popsicles as popsicles, only about 40% of the things we labeled popsicles were popsicles. If we examine the classification matrix above, we see that many string beans and peanuts were also labeled as popsicles.
We also plot a random sample of mis-classified doodles to get a sence of where we might be going wrong.
Figure 4: A Sampler of Misclassified Foods
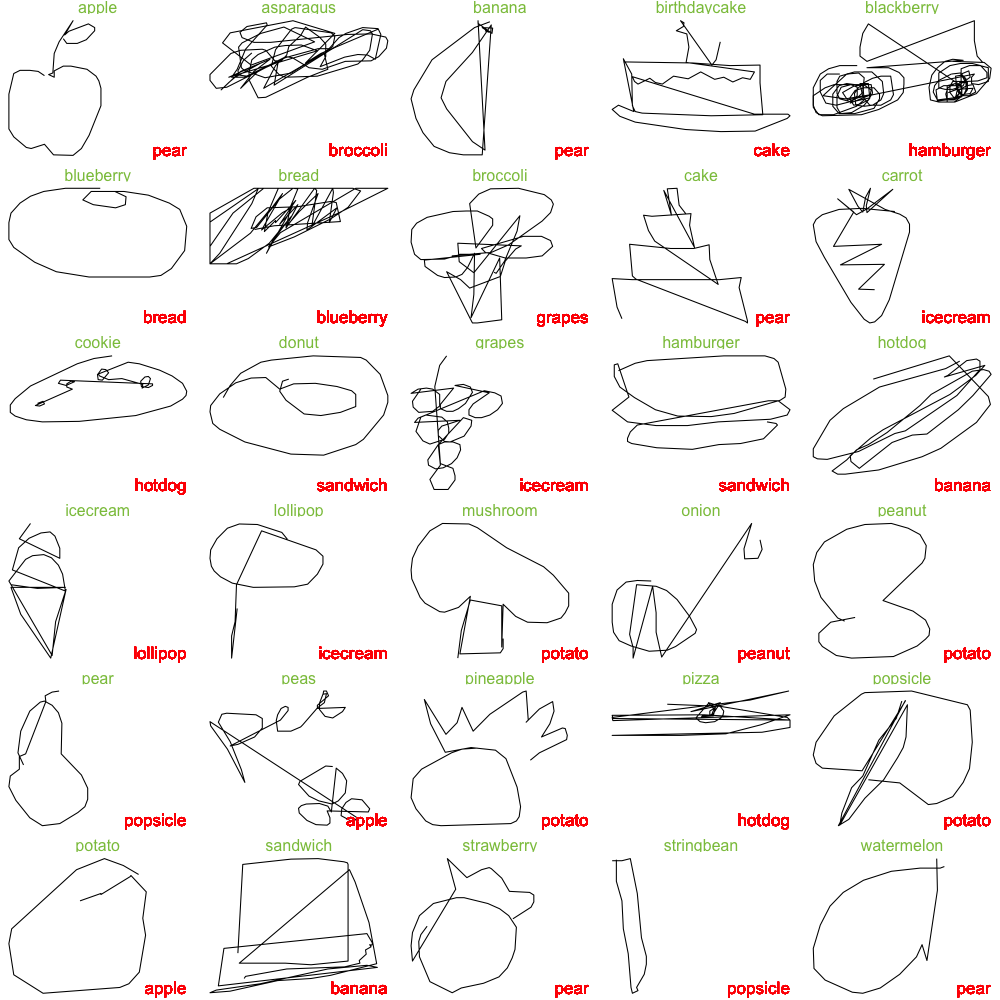
In the sample above, the true labels are given in green text while the classifications are given in red. From the sample above, we see that most of the misclassified images are recognizeable to the human eye, with the exception of the watermelon, sandwich, potato, popsicle, pizza, onion, bread, asparagus, and blackberry (9/30 images).
Extending the Model
Our exploratory data analysis demonstrated a high degree of rotational variability in some food classes, such as the banana, asparagus, carrot, string bean, potato, and peanut. Other food classes seemed to be made up of multiple food sub-classes (pizza and watermelon). Hence, incorporating rotatinal variability and sub-classes into our model might improve our predictions.
We consider comparing the following prediction pipelines:
The original model (as demonstrated above). We compare the un-transformed image to the raw kernels.
The rotation model. We compare the PCA-rotated image (described in the EDA) to the Pre-rotated kernels.
The combined model. We take whichever label from class one or two that produced a higher log likelihood.
The rotation model with clusters. We add kernels for each subclass that we generated by clustering. We in addition to comparing the raw data to the raw kernels and the rotated data to the rotated kernels, we compare the rotated data to the cluster-generated kernels.
The cherry picked model For each food class, we pick the kernel which we think best represents the data (raw, rotated, or rotated and clustered). We only compare a raw doodle to the raw kernels we have chosen and the rotated doodle to the rotated kernels we have chosen.
We were surprised that our predictions did not get any better by considering rotations, clustering, or human selection of rotated vs. raw vs. cluster-derived kernels.
Table 1: Model Accuracy
| Model | Accuracy |
|---|---|
| 1 | 0.35 |
| 2 | 0.19 |
| 3 | 0.32 |
| 4 | 0.32 |
| 5 | 0.27 |
The table above gives the accuracy for the five models. Rotating all of the images for prediction and kernel estimation reduced the overall accuracy dramatically to only 19%.
Figure 5: Accuracy by Model and Class
Using Figure 5, we can examine the class-specific accuracy of our 5 models. We see that the rotation fufilled its purposes for the food classes that needed it. In our exploratory data analysis, we saw that the kernels for peanuts, potatos, and string beans became much clearer when we rotated the data. Here, we see the accuracy of model 2 is better than model 1 for those classes. Additionally, we see that the accuracy for watermelon, pizza, bananas, and bread improves when we include the cluster-derived kernels in model 4. However, these improvements all seem to come at a cost–the predictions for the other classes fall.
Figure 6: Comparing Model 1 vs 5
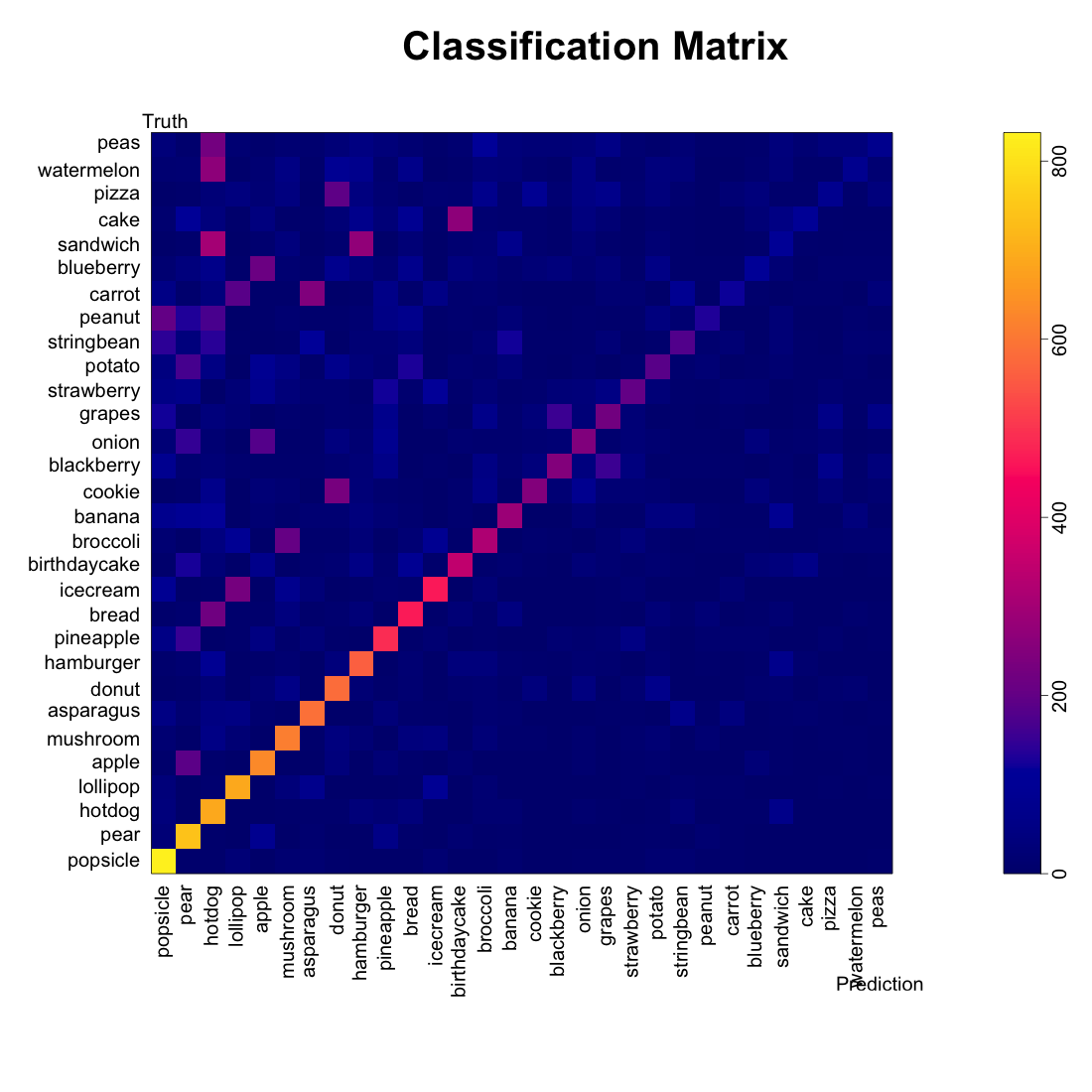
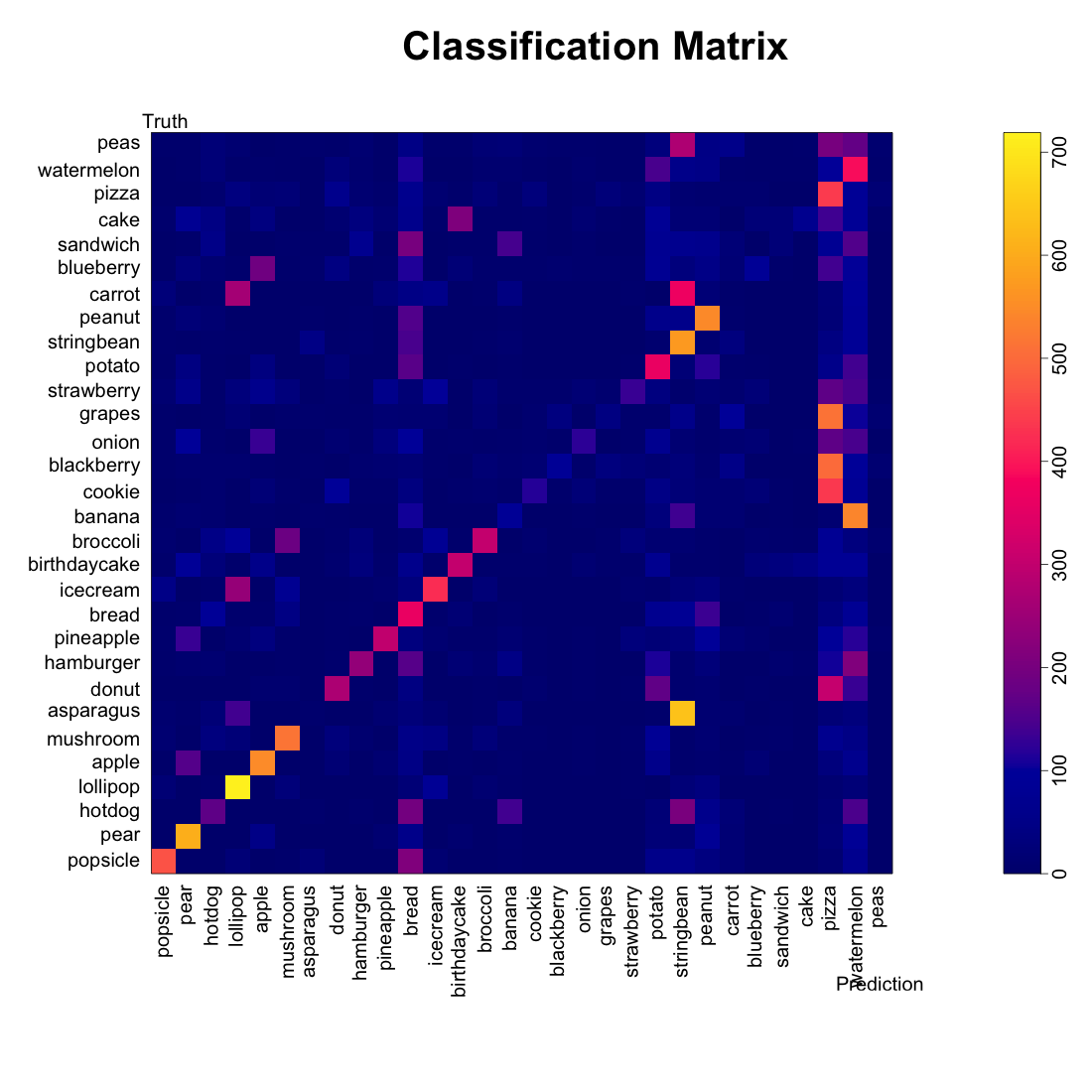
When we examine the prediction matricies side-by-side, we see something strange about the food classes with kernels constructed after clustering or rotating. They seem to “absorb” predictions from some of the other classes. Cookies, blackberries, grapes, doughnuts, and peas are often misclassified as pizzas.
Discussion and Take-Aways
The performance of this model was pretty abysmal compared to a convolutional neural network. We truly were suprised by how badly it performed, even after incorporating extra data processing. However, our model DID incorporate an important idea: keeping the data small.
For most traditional image processing and classification, the images need to be in a raster format. For each image on a 256 x 256 grid, the computer has to store 65,536 numbers. However, we retained the data format provided by Google, which stores the images as roughly 50 ordered (x,y) pairs. Hence, we could could easily work with 5,000 images from 30 classes (only 1.5 million numbers) all at once in R.
Building Model 1 from 150,000 images and testing it on 30,000 images took less than a minute (in computer time). In comparison, fitting a neural network from a fraction of these images at a reduced quality (32 x 32 pixels) took days. Incorporating the PCA-based rotations in Models 2-5 increased our computation time substantially, but everything could still be handled in less than 30 minutes.
Ideally, there could be some happy medium between these two approaches: a neural network that could utilize the smaller dimensionality of the path-style image data. Given more time on this project, we would also consider exploring some wavelet and shapelet based machine learning algorithms.